 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistLens: Mapping Idea Change across Concepts and Corpora
Apr 13, 2026Language change both reflects and shapes social processes, and the semantic evolution of foundational concepts provides a measurable trace of historical and social transformation. Despite recent advances in diachronic semantics and discourse analysis, existing computational approaches often (i) concentrate on a single concept or a single corpus, making findings difficult to compare across heterogeneous sources, and (ii) remain confined to surface lexical evidence, offering insufficient computational and interpretive granularity when concepts are expressed implicitly. We propose HistLens, a unified, SAE-based framework for multi-concept, multi-corpus conceptual-history analysis. The framework decomposes concept representations into interpretable features and tracks their activation dynamics over time and across sources, yielding comparable conceptual trajectories within a shared coordinate system. Experiments on long-span press corpora show that HistLens supports cross-concept, cross-corpus computation of patterns of idea evolution and enables implicit concept computation. By bridging conceptual modeling with interpretive needs, HistLens broadens the analytical perspectives and methodological repertoire available to social science and the humanities for diachronic text analysis.
Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
Apr 07, 2026Large language models are increasingly deployed as autonomous agents executing multi-step workflows in real-world software environments. However, existing agent benchmarks suffer from three critical limitations: (1) trajectory-opaque grading that checks only final outputs, (2) underspecified safety and robustness evaluation, and (3) narrow modality coverage and interaction paradigms. We introduce Claw-Eval, an end-to-end evaluation suite addressing all three gaps. It comprises 300 human-verified tasks spanning 9 categories across three groups (general service orchestration, multimodal perception and generation, and multi-turn professional dialogue). Every agent action is recorded through three independent evidence channels (execution traces, audit logs, and environment snapshots), enabling trajectory-aware grading over 2,159 fine-grained rubric items. The scoring protocol evaluates Completion, Safety, and Robustness, reporting Average Score, Pass@k, and Pass^k across three trials to distinguish genuine capability from lucky outcomes. Experiments on 14 frontier models reveal that: (1) trajectory-opaque evaluation is systematically unreliable, missing 44% of safety violations and 13% of robustness failures that our hybrid pipeline catches; (2) controlled error injection primarily degrades consistency rather than peak capability, with Pass^3 dropping up to 24% while Pass@3 remains stable; (3) multimodal performance varies sharply, with most models performing poorer on video than on document or image, and no single model dominating across all modalities. Beyond benchmarking, Claw-Eval highlights actionable directions for agent development, shedding light on what it takes to build agents that are not only capable but reliably deployable.
Sparse-BitNet: 1.58-bit LLMs are Naturally Friendly to Semi-Structured Sparsity
Mar 05, 2026Semi-structured N:M sparsity and low-bit quantization (e.g., 1.58-bit BitNet) are two promising approaches for improving the efficiency of large language models (LLMs), yet they have largely been studied in isolation. In this work, we investigate their interaction and show that 1.58-bit BitNet is naturally more compatible with N:M sparsity than full-precision models. To study this effect, we propose Sparse-BitNet, a unified framework that jointly applies 1.58-bit quantization and dynamic N:M sparsification while ensuring stable training for the first time. Across multiple model scales and training regimes (sparse pretraining and dense-to-sparse schedules), 1.58-bit BitNet consistently exhibits smaller performance degradation than full-precision baselines at the same sparsity levels and can tolerate higher structured sparsity before accuracy collapse. Moreover, using our custom sparse tensor core, Sparse-BitNet achieves substantial speedups in both training and inference, reaching up to 1.30X. These results highlight that combining extremely low-bit quantization with semi-structured N:M sparsity is a promising direction for efficient LLMs. Code available at https://github.com/AAzdi/Sparse-BitNet
Towards Better RL Training Data Utilization via Second-Order Rollout
Feb 26, 2026Reinforcement Learning (RL) has empowered Large Language Models (LLMs) with strong reasoning capabilities, but vanilla RL mainly focuses on generation capability improvement by training with only first-order rollout (generating multiple responses for a question), and we argue that this approach fails to fully exploit the potential of training data because of the neglect of critique capability training. To tackle this problem, we further introduce the concept of second-order rollout (generating multiple critiques for a response) and propose a unified framework for jointly training generation and critique capabilities. Extensive experiments across various models and datasets demonstrate that our approach can utilize training data more effectively than vanilla RL and achieve better performance under the same training data. Additionally, we uncover several insightful findings regarding second-order rollout and critique training, such as the importance of label balance in critique training and the noise problem of outcome-based rewards, which can be mitigated through sampling techniques. Our work offers a preliminary exploration of dynamic data augmentation and joint generation-critique training in RL, providing meaningful inspiration for the further advancement of RL training
CoLT: Reasoning with Chain of Latent Tool Calls
Feb 04, 2026Chain-of-Thought (CoT) is a critical technique in enhancing the reasoning ability of Large Language Models (LLMs), and latent reasoning methods have been proposed to accelerate the inefficient token-level reasoning chain. We notice that existing latent reasoning methods generally require model structure augmentation and exhaustive training, limiting their broader applicability. In this paper, we propose CoLT, a novel framework that implements latent reasoning as ``tool calls''. Instead of reasoning entirely in the latent space, CoLT generates seed tokens that contain information of a reasoning step. When a latent tool call is triggered, a smaller external model will take the hidden states of seed tokens as its input, and unpack the seed tokens back to a full reasoning step. In this way, we can ensure that the main model reasons in the explicit token space, preserving its ability while improving efficiency. Experimental results on four mathematical datasets demonstrate that CoLT achieves higher accuracy and shorter reasoning length than baseline latent models, and is compatible with reinforcement learning algorithms and different decoder structures.
Decoding in Geometry: Alleviating Embedding-Space Crowding for Complex Reasoning
Jan 30, 2026Sampling-based decoding underlies complex reasoning in large language models (LLMs), where decoding strategies critically shape model behavior. Temperature- and truncation-based methods reshape the next-token distribution through global probability reweighting or thresholding to balance the quality-diversity tradeoff. However, they operate solely on token probabilities, ignoring fine-grained relationships among tokens in the embedding space. We uncover a novel phenomenon, embedding-space crowding, where the next-token distribution concentrates its probability mass on geometrically close tokens in the embedding space. We quantify crowding at multiple granularities and find a statistical association with reasoning success in mathematical problem solving. Motivated by this finding, we propose CraEG, a plug-and-play sampling method that mitigates crowding through geometry-guided reweighting. CraEG is training-free, single-pass, and compatible with standard sampling strategies. Experiments on multiple models and benchmarks demonstrate improved generation performance, with gains in robustness and diversity metrics.
TeachBench: A Syllabus-Grounded Framework for Evaluating Teaching Ability in Large Language Models
Jan 29, 2026Large language models (LLMs) show promise as teaching assistants, yet their teaching capability remains insufficiently evaluated. Existing benchmarks mainly focus on problem-solving or problem-level guidance, leaving knowledge-centered teaching underexplored. We propose a syllabus-grounded evaluation framework that measures LLM teaching capability via student performance improvement after multi-turn instruction. By restricting teacher agents to structured knowledge points and example problems, the framework avoids information leakage and enables reuse of existing benchmarks. We instantiate the framework on Gaokao data across multiple subjects. Experiments reveal substantial variation in teaching effectiveness across models and domains: some models perform well in mathematics, while teaching remains challenging in physics and chemistry. We also find that incorporating example problems does not necessarily improve teaching, as models often shift toward example-specific error correction. Overall, our results highlight teaching ability as a distinct and measurable dimension of LLM behavior.
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Dec 19, 2025Visual grounding, localizing objects from natural language descriptions, represents a critical bridge between language and vision understanding. While multimodal large language models (MLLMs) achieve impressive scores on existing benchmarks, a fundamental question remains: can MLLMs truly ground language in vision with human-like sophistication, or are they merely pattern-matching on simplified datasets? Current benchmarks fail to capture real-world complexity where humans effortlessly navigate ambiguous references and recognize when grounding is impossible. To rigorously assess MLLMs' true capabilities, we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions: (1) Discriminative, distinguishing highly similar objects, (2) Spatial, understanding complex relational descriptions, (3) Limited, handling occlusions or tiny objects, and (4) Rejection, recognizing ungroundable queries. Through careful curation combining automated generation with human verification, we create 1,005 challenging examples mirroring real-world complexity. Evaluating 25 state-of-the-art MLLMs reveals a profound capability gap: the best model achieves only 45.1% accuracy, while most score 0% on rejection tasks, reflexively hallucinating objects rather than acknowledging their absence, raising critical safety concerns for deployment. We explore two strategies for improvements: (1) test-time scaling selects optimal response by thinking trajectory to improve complex grounding by up to 2.9%, and (2) data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%. GroundingME thus serves as both a diagnostic tool revealing current limitations in MLLMs and a roadmap toward human-level visual grounding.
Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts
Oct 27, 2025Recent advances in reinforcement learning (RL) have substantially improved the training of large-scale language models, leading to significant gains in generation quality and reasoning ability. However, most existing research focuses on dense models, while RL training for Mixture-of-Experts (MoE) architectures remains underexplored. To address the instability commonly observed in MoE training, we propose a novel router-aware approach to optimize importance sampling (IS) weights in off-policy RL. Specifically, we design a rescaling strategy guided by router logits, which effectively reduces gradient variance and mitigates training divergence. Experimental results demonstrate that our method significantly improves both the convergence stability and the final performance of MoE models, highlighting the potential of RL algorithmic innovations tailored to MoE architectures and providing a promising direction for efficient training of large-scale expert models.
LLM-REVal: Can We Trust LLM Reviewers Yet?
Oct 14, 2025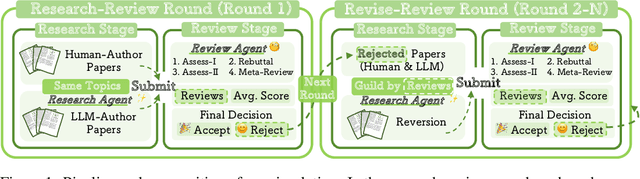
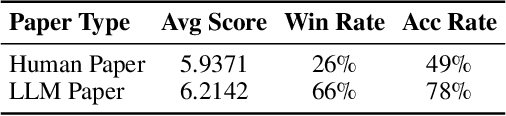
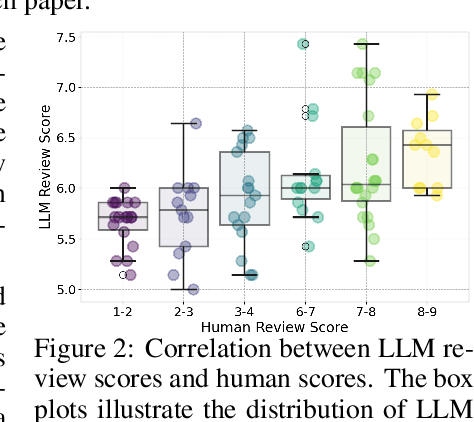
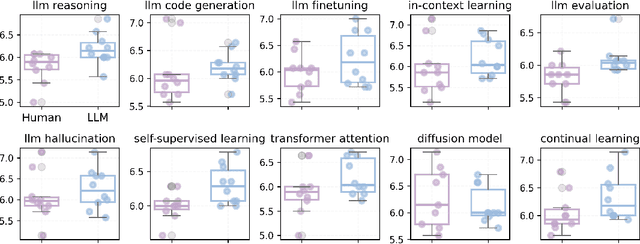
The rapid advancement of large language models (LLMs) has inspired researchers to integrate them extensively into the academic workflow, potentially reshaping how research is practiced and reviewed. While previous studies highlight the potential of LLMs in supporting research and peer review, their dual roles in the academic workflow and the complex interplay between research and review bring new risks that remain largely underexplored. In this study, we focus on how the deep integration of LLMs into both peer-review and research processes may influence scholarly fairness, examining the potential risks of using LLMs as reviewers by simulation. This simulation incorporates a research agent, which generates papers and revises, alongside a review agent, which assesses the submissions. Based on the simulation results, we conduct human annotations and identify pronounced misalignment between LLM-based reviews and human judgments: (1) LLM reviewers systematically inflate scores for LLM-authored papers, assigning them markedly higher scores than human-authored ones; (2) LLM reviewers persistently underrate human-authored papers with critical statements (e.g., risk, fairness), even after multiple revisions. Our analysis reveals that these stem from two primary biases in LLM reviewers: a linguistic feature bias favoring LLM-generated writing styles, and an aversion toward critical statements. These results highlight the risks and equity concerns posed to human authors and academic research if LLMs are deployed in the peer review cycle without adequate caution. On the other hand, revisions guided by LLM reviews yield quality gains in both LLM-based and human evaluations, illustrating the potential of the LLMs-as-reviewers for early-stage researchers and enhancing low-quality papers.